Recommender¶
-
class
openrec.legacy.recommenders.Recommender(batch_size, max_user, max_item, extra_interactions_funcs=[], extra_fusions_funcs=[], test_batch_size=None, l2_reg=None, opt='SGD', lr=None, init_dict=None, sess_config=None)¶ The Recommender is the OpenRec abstraction [1] for recommendation algorithms.
Parameters: - batch_size (int) – Training batch size. The structure of a training instance varies across recommenders.
- max_user (int) – Maximum number of users in the recommendation system.
- max_item (int) – Maximum number of items in the recommendation system.
- extra_interactions_funcs (list, optional) – List of functions to build extra interaction modules.
- extra_fusions_funcs (list, optional) – List of functions to build extra fusion modules.
- test_batch_size (int, optional) – Batch size for testing and serving. The structure of a testing/serving instance varies across recommenders.
- l2_reg (float, optional) – Weight for L2 regularization, i.e., weight decay.
- opt ('SGD'(default) or 'Adam', optional) – Optimization algorithm, SGD: Stochastic Gradient Descent.
- init_dict (dict, optional) – Key-value pairs for initial parameter values.
- sess_config (tensorflow.ConfigProto(), optional) – Tensorflow session configuration.
Notes
The recommender abstraction defines the procedures to build a recommendation computational graph and exposes interfaces for training and evaluation. During training, for each batch, the
self.trainfunction should be called with abatch_datainput,recommender_instance.train(batch_data)
and during testing/serving, the serve function should be called with a batch_data input:
recommender_instance.serve(batch_data)
A recommender contains four major components: inputs, extractions, fusions, and interactions. The figure below shows the order of which each related function is called. The
trainparameter in each function is used to build different computational graphs for training and serving.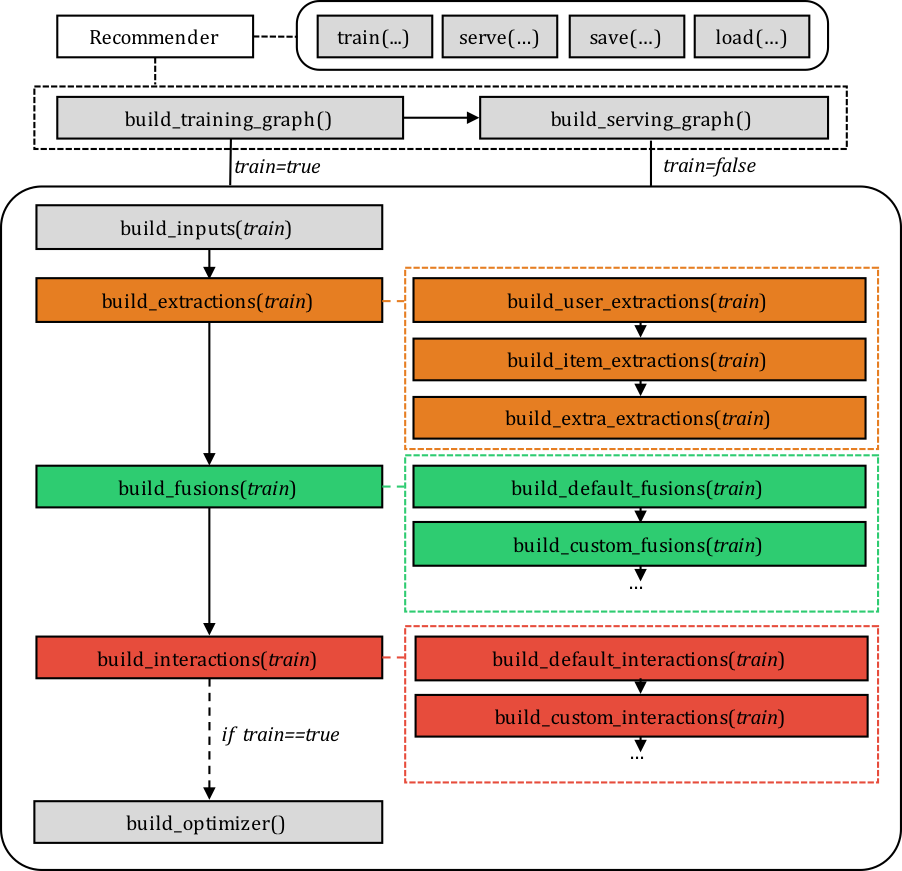
A new recommender class should be inherent from the Recommender class. Follow the steps below to override corresponding functions. To make a recommender easily extensible, it is NOT recommended to override functions
self._build_inputs,self._build_fusions, andself._build_interactions.- Define inputs. Override functions
self._build_user_inputs,self._build_item_inputs, andself._build_extra_inputsto define inputs for users’, items’, and contextual data sources respectively. An input should be defined using the input function as follows.
self._add_input(name='input_name', dtype='float32', shape=data_shape, train=True)
- Define input mappings. Override the function
self._input_mappingsto feed a batch_data into the defined inputs. The mapping should be specified using a python dict where a key corresponds to an input object retrieved byself._get_input(input_name, train=train), and a value corresponds to abatch_datavalue. - Define extraction modules. Override functions
self._build_user_extractions,self._build_item_extractions, andself._build_extra_extractionsto define extraction modules for users, items, and extra contexts respectively. Useself._add_moduleto construct a module, andself._get_input/self._get_moduleto retrieve an existing input/module. - Define fusion modules. Override the function
self._build_default_fusionsto build fusion modules. Custom functions can also be used as long as they are included in the inputextra_fusions_funcslist. Useself._add_moduleto construct a module, andself._get_input/self._get_moduleto retrieve an existing input/module. - Define interaction modules. Override the fuction
build_default_interactionsto build interaction modules. Custom functions can also be used as long as they are included in the inputextra_interactions_funcslist. Useself._add_moduleto construct a module, andself._get_input/self._get_moduleto retrieve an existing input/module.
When (
train==False), a variable namedself._scoresshould be defined for user-item scores. Such a score is higher if an item should be ranked higher in the recommendation list.References
[1] Yang, L., Bagdasaryan, E., Gruenstein, J., Hsieh, C., and Estrin, D., 2018, June. OpenRec: A Modular Framework for Extensible and Adaptable Recommendation Algorithms. In Proceedings of WSDM‘18, February 5-9, 2018, Marina Del Rey, CA, USA. -
_add_input(name, dtype='float32', shape=None, train=True)¶ Add an input - overwrite if
nameexists.Parameters: - name (str) – The input name.
- dtype (str) – Data type: “float16”, “float32” (default), “float64”, “int8”, “int16”, “int32”, “int64”, “bool”, “string” or “none”.
- shape (list or tuple) – Input shape.
- train (bool) – Specify training or serving graph.
-
_add_module(name, module, train_loss=None, train=True)¶ Add a module - overwrite if
nameexists.Parameters: - name (str) – Module name.
- module (Module) – Module instance.
- train_loss (bool, optional) – Whether or not to include the output loss in the training loss (Default: include losses from all modules).
- train (bool, optional) – Specify the computational graph (train/serving) to add the module.
-
_build_default_fusions(train=True)¶ Build default fusion modules (may be overriden).
Parameters: train (bool) – An indicator for training or servining phase.
-
_build_default_interactions(train=True)¶ Build default interaction modules (may be overriden).
Parameters: train (bool) – An indicator for training or servining phase.
-
_build_extra_extractions(train=True)¶ Build extraction modules for contextual data sources (may be overriden)
Parameters: train (bool) – An indicator for training or servining phase.
-
_build_extra_inputs(train=True)¶ Build inputs for contextual data sources (should be overriden)
Parameters: train (bool) – An indicator for training or servining phase.
-
_build_extractions(train=True)¶ Call sub-functions to build extractions (do NOT override).
Parameters: train (bool) – An indicator for training or servining phase.
-
_build_fusions(train=True)¶ Call sub-functions to build fusions (do NOT override).
Parameters: train (bool) – An indicator for training or servining phase.
-
_build_inputs(train=True)¶ Call sub-functions to build inputs (do NOT override).
Parameters: train (bool) – An indicator for training or servining phase.
-
_build_interactions(train=True)¶ Call sub-functions to build interactions (do NOT override).
Parameters: train (bool) – An indicator for training or servining phase.
-
_build_item_extractions(train=True)¶ Build extraction modules for items’ data sources (should be overriden)
Parameters: train (bool) – An indicator for training or servining phase.
-
_build_item_inputs(train=True)¶ Build inputs for items’ data sources (should be overriden)
Parameters: train (bool) – An indicator for training or servining phase.
-
_build_optimizer()¶ Build an optimizer for model training.
-
_build_post_training_graph()¶ Build post-training graph (do NOT override).
-
_build_post_training_ops()¶ Build post-training operators (may be overriden).
Returns: A list of Tensorflow operators. Return type: list
-
_build_serving_graph()¶ Call sub-functions to build serving graph (do NOT override).
-
_build_training_graph()¶ Call sub-functions to build training graph (do NOT override).
-
_build_user_extractions(train=True)¶ Build extraction modules for users’ data sources (should be overriden)
Parameters: train (bool) – An indicator for training or servining phase.
-
_build_user_inputs(train=True)¶ Build inputs for users’ data sources (should be overriden)
Parameters: train (bool) – An indicator for training or servining phase.
-
_get_input(name, train=True)¶ Retrieve an input.
Parameters: - name (str) – Input name.
- train (bool) – Specify training or serving graph.
Returns: The input specified by the name and the
trainflag.Return type: Tensorflow placeholder
-
_get_module(name, train=True)¶ Retrieve a module.
Parameters: - name (str) – The module name.
- train (bool) – Specify training or serving graph.
Returns: The module specified by the name and the
trainflag.Return type:
-
_grad_post_processing(grad_var_list)¶ Post-process gradients before updating variables.
Parameters: grad_var_list (list) – A list of tuples (gradients, variable). Returns: A list of updated tuples (updated gradients, variables). Return type: list
-
_initialize(init_dict)¶ Initialize model parameters (do NOT override).
Parameters: init_dict (dict) – Key-value pairs for initial parameter values.
-
_input(dtype='float32', shape=None, name=None)¶ Define an input for the recommender.
Parameters: - dtype (str) – Data type: “float16”, “float32”, “float64”, “int8”, “int16”, “int32”, “int64”, “bool”, or “string”.
- shape (list or tuple) – Input shape.
- name (str) – Name of the input.
Returns: Defined tensorflow placeholder.
Return type: Tensorflow placeholder
-
_input_mappings(batch_data, train)¶ Define mappings from input training batch to defined inputs.
Parameters: - batch_data (dict) – A training batch.
- train (bool) – An indicator for training or servining phase.
Returns: The mapping where a key corresponds to an input object, and a value corresponds to a
batch_datavalue.Return type: dict
-
compute_module_loss(name, batch_data, train=True)¶ Compute the loss of a module, specified by the name and the train flag.
Parameters: - name (str) – The module name.
- batch_data (dict) – A batch of training or serving data.
- train (bool) – Specify the computational graph (train/serving) to compute loss.
Returns: The loss of the specified module.
Return type: Numpy array
-
compute_module_outputs(name, batch_data, train=True)¶ Compute the outputs of a module, specified by the name and the train flag.
Parameters: - name (str) – The module name.
- batch_data (dict) – A batch of training or serving data.
- train (bool) – Specify the computational graph (train/serving) to compute outputs.
Returns: The outputs of the specified module.
Return type: A list of Numpy arrays
-
load(load_dir)¶ Load a saved model from disk.
Parameters: load_str (str) – Path to the saved model.
-
save(save_dir, step)¶ Save a trained model to disk.
Parameters: - save_str (str) – Path to save the model.
- step (int) – training step.
-
serve(batch_data)¶ Evaluate the model with an input batch_data.
Parameters: batch_data (dict) – A batch of testing or serving data.
-
train(batch_data)¶ Train the model with an input batch_data.
Parameters: batch_data (dict) – A batch of training data.